
在“HashMap 如何在 Java 中工作“,我们了解了 HashMap 或 ConcurrentHashMap 类的内部结构,以及它们如何融入整个概念。但是当面试官问你HashMap相关概念的时候,他不会只停留在核心概念上。讨论通常会从多个方向进行,以了解您是否真正理解这个概念。
在这篇文章中,我们将尝试涵盖一些关于 HashMap 和 ConcurrentHashMap 的相关面试问题。
1、如何为HashMap设计一个好的key
设计一个好的键的最基本需求是“我们应该能够从地图中检索值对象而不会失败”,对吗?否则无论你构建多么花哨的数据结构,它都没有用。
Key 的 hashcode() 主要与其 equals() 方法结合使用,用于将键放入 Map,然后从地图。因此,如果在我们将键值对放入 Map 之后 key 对象的哈希码发生变化,那么几乎不可能从 < em>地图。它还会导致内存泄漏。为避免这种情况,映射键应该是不可变的。这些是 的一些内容创建一个不可变类。
这就是为什么不可变类如 String、Integer 或其他 包装类 是创建映射键的良好候选者。
但请记住,不可变性是推荐的,但不是强制性的。如果我们想将一个可变对象作为 Map 中的键,那么我们必须确保键对象的状态变化不会改变对象的哈希码。这可以通过覆盖 hashCode() 方法来完成。此外,关键类必须遵守 hashCode() 和equals() 方法收缩 以避免在运行时出现不希望的和令人惊讶的行为。
此处< /a>。
2、HashMap和ConcurrentHashMap的区别?
为了更好地可视化 ConcurrentHashMap,将其视为一组 HashMap 实例。要从 hashmap 获取和放置键值对,我们必须计算 hashcode 并在 Collection.Entry 数组中寻找正确的桶位置。
在ConcurrentHashMap中,区别在于存储这些键值对的内部结构。 ConcurrentHashMap 有一个额外的段概念。
你认为one segment equal to one HashMap [conceptually]会更容易理解。 concurrentHashMap 在初始化时被分成多个段 [默认 16]。 ConcurrentHashMap 允许相似数量(16)的线程并发访问这些段,以便每个线程在高并发时工作在特定的段上。
这样,如果当你的键值对存储在第 10 段时;代码不需要另外阻塞其他 15 个段。这种结构提供了非常高的并发性。
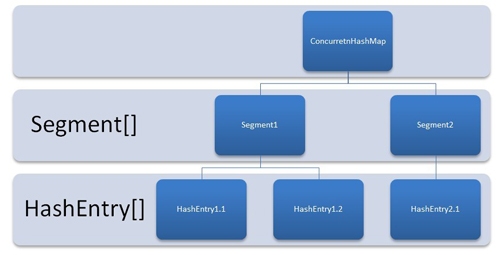 <图解说明> ConcurrentHashMap 内部结构
<图解说明> ConcurrentHashMap 内部结构
换句话说,ConcurrentHashMap 使用了多个锁,每个锁控制一个映射段。在特定段中设置数据时,将获得该段的锁。所以本质上更新操作是同步的。
获取数据时,使用volatile read,没有任何同步。如果易失性读取导致未命中,则获取该段的锁并再次在同步块中搜索条目。
3、HashMap和Collections.synchronizedMap()的区别?
HashMap 是非同步的 并且 Collections.synchronizedMap() 返回一个包含所有 get 的 HashMap 包装实例, put 方法同步。
本质上,Collections.synchronizedMap() 返回内部创建的内部类“SynchronizedMap”的引用,它包含作为参数传递的输入 HashMap 的键值对。
该内部类实例与原参数HashMap实例无关,完全独立。
4.ConcurrentHashMap和Collections.synchronizedMap()的区别?
这是一个稍微复杂的问题。两者都是HashMap的同步版本,核心功能和内部结构不同。
如上所述,ConcurrentHashMap 由内部段组成,在概念上可以将其视为独立的 HashMap 实例。所有这些段都可以在高并发执行中被单独的线程锁定。这样,多个线程可以从 ConcurrentHashMap 中获取/放入键值对,而不会相互阻塞/等待。
在 Collections.synchronizedMap() 中,我们获得了 HashMap 的同步版本,并且以阻塞方式访问它。这意味着如果多个线程尝试同时访问 synchronizedMap,它们将被允许以同步方式一次获取/放置一个键值对。
5.HashMap和HashTable的区别
这也是很容易的问题。主要区别是HashTable 是同步的而HashMap 不是。
如果询问其他原因,请告诉他们,HashTable 是遗留类(JDK 1.0 的一部分),后来通过实现 Map 接口被提升为集合框架。它仍然有一些额外的特性,比如枚举器,这是 HashMap 所缺乏的。
另一个次要原因可能是:HashMap 支持空键(映射到零桶),HashTable 不支持空键并在此类尝试时抛出 NullPointerException。
6. HashTable和Collections.synchronized(Map)的区别?
两者都是集合的同步版本。两者在类中都有同步方法。两者本质上都是阻塞的,即多个线程在从实例中放入/取出任何东西之前需要等待获得实例上的锁。
那么区别是什么呢。好吧,由于上述原因,没有重大差异。两个系列的性能也相同。
唯一将它们分开的是 HashTable 是旧的 类被提升为集合框架这一事实。它有自己的额外功能,如枚举器。
7.随机或固定哈希码()的影响?
两种情况(键的固定哈希码或随机哈希码)的影响将产生相同的结果,即“意外行为”。 HashMap 中 hashcode 的最基本需求是识别存储桶位置,将键值对放在哪里,以及从哪里检索它。
如果key对象的hashcode每次都变了,每次计算的key-value对的具体位置都会不一样。这样一来,HashMap中存储的一个对象就永远丢失了,就会有很多从地图上取回它的可能性最小。
如果 hashcode() 是所有对象的固定值,那么所有对象将存储在单个桶中,这会降低 Map 性能。
出于同样的原因,建议密钥是不可变的,这样每次在同一密钥对象上请求时,它们都会返回一个唯一且相同的哈希码。
8. 并发应用中可以使用HashMap吗?
在正常情况下,并发访问会使哈希映射处于不一致状态,其中添加和检索的键值对可能不同。除此之外,还有其他令人惊讶的行为,例如 NullPointerException。
在最坏的情况下,可能会导致死循环。是的。你做对了。它会导致无限循环。你问什么,如何?好吧,这就是原因。
HashMap 具有在达到其大小上限时重新散列 的概念。这个rehashing就是创建一个新的内存区域,把所有已经存在的键值对复制到新的内存区域中。
假设线程 A 尝试将键值对放入 map 中,然后开始重新散列。与此同时,线程 B 出现并开始使用 put() 操作来操作桶。
这里在重新散列过程中,有机会生成循环依赖,其中链表中的一个元素 [在任何桶中] 可以指向同一桶中的任何先前节点。这将导致无限循环,因为重新散列代码包含“while(true) { //get next node; }”块,并且在循环依赖中它将无限运行。
要仔细观察,请查看 rehashing 中使用的传输方法的源代码:
public Object get(Object key) {
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
Entry e = table[i];
//While true is always a bad practice and cause infinite loops
while (true) {
if (e == null)
return e;
if (e.hash == hash & eq(k, e.key))
return e.value;
e = e.next;
}
}我希望我能够在您的知识桶中添加更多关于hashmap 面试问题 和ConcurrentHashMap 面试问题 的内容。如果您觉得这篇文章有帮助,请考虑与您的朋友分享。
快乐学习!!
地址:https://www.cundage.com/article/hashmap-concurrenthashmap-interview-questions.html
相关阅读
