
Java HashMap 是 Collections 框架 的成员,用于存储键值对。每个键映射到单个值,并且不允许重复键。在本教程中,我们将了解HashMap 如何在内部存储键值对以及它如何防止重复键。
一、内部数据结构
HashMap 是Map 接口的哈希表实现。哈希表使用哈希函数计算一个索引,也称为哈希码,到一个数组中buckets 或 slots,可以从中找到所需的值。在查找期间,对提供的键进行哈希处理,生成的哈希值指示相应值在哈希表中的存储位置。

为了将所有东西放在一起,Java Map 定义了一个类型为 Map.Entry 的内部类 Node。它存储键、生成的散列(避免每次比较时都计算散列)、值和指向下一个节点的指针。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//other code
}如上所示,多个键可以生成将它们映射到单个存储桶中的散列。在这种情况下,Map 条目存储为 LinkedList。
但是,当单个桶中的条目达到阈值(TREEIFY_THRESHOLD,默认值 8)时,Map 会将桶的内部结构从链表转换为 RedBlackTree(JEP 180)。所有 Entry 实例都转换为 TreeNode 实例。
基本上,当桶变得太大时,HashMap 会动态地将其替换为 TreeMap 的临时实现。这样,我们得到的 O(log n) 要好得多,而不是悲观的 O(n) 性能。
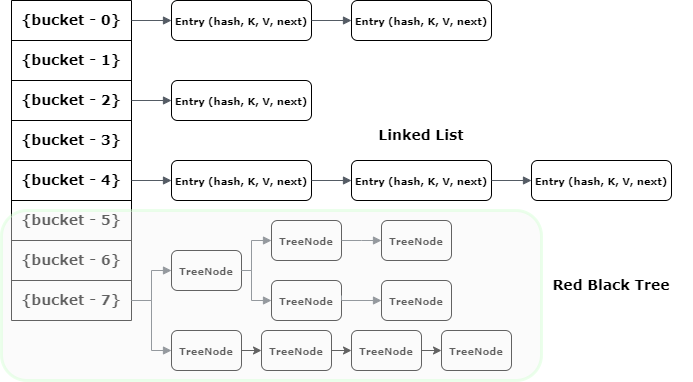
请注意,当桶中的节点减少小于 UNTREEIFY_THRESHOLD 时,Tree 再次转换为 LinkedList。这有助于平衡性能与内存使用,因为 TreeNodes 比 Map.Entry 实例占用更多内存。因此,Map 只有在以内存浪费换取可观的性能提升时才使用 Tree。
2. 内部散列
最简单的散列法是一种在将公式/算法应用于对象属性后为其分配唯一代码的方法。
真正的哈希函数应该在每次将函数应用于相同或相等的对象时返回相同的哈希码。换句话说,两个相等的对象必须一致地产生相同的散列码。
在 Java 中,所有对象都继承 hashCode() 类中定义的 Object 函数的默认实现。它通常通过将对象的内部地址转换为整数来生成哈希码,从而为所有不同的对象生成不同的哈希码。
public class Object {
public native int hashCode();
}Java 设计者明白最终用户创建的对象可能不会生成均匀分布的散列码,因此 Map 类在内部对键的 hashcode() 应用另一轮散列函数来生成它们分布合理。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}这是 final hash,从 Key 对象的初始 hash 生成,用于查找 bucket 位置。
3. put() API 是如何工作的?
到目前为止,我们了解到每个 Java 对象都有一个与之相关联的唯一哈希码,该哈希码用于决定 HashMap 中将存储键值对的存储桶位置。
在进入 put() 方法的实现之前,了解 Node 类的实例存储在数组中是非常重要的。 数组中的每个索引位置都被视为一个桶:
transient Node<K,V>[] table;要存储键值对,我们调用 put() API,如下所示:
V put(K key, V value);put() API 在内部首先使用 key.hashcode() 方法计算初始哈希值,然后使用 hash() 上一节中讨论的方法。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}这个最终哈希值最终用于计算数组或存储桶位置中的索引。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}4. 如何解决冲突?
现在是主要部分,因为我们知道两个不相等的对象可以具有相同的哈希码值,两个不同的对象将如何存储在称为 bucket 的相同数组位置。
如果您还记得,Node 类有一个属性 "next"。此属性始终指向链中的下一个对象。因此,所有具有相同键的节点都以 LinkedList 的形式存储在相同的数组索引中。
当需要将 Node 对象存储在特定索引处时,HashMap 会检查数组索引中是否已经存在一个 Node? ?如果不存在 Node,则当前 Node 对象存储在此位置。如果对象已经位于计算索引上,则检查其next 属性。如果是null,则当前Node对象成为LinkedList中的下一个节点。如果next变量不是null,则继续执行直到next 被计算为 null。
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
break;
} 请注意,如果存储桶中的第一个节点是 TreeNode 类型,则 TreeNode.putTreeVal() 用于在红黑树中插入一个新节点。
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 5. get() API 是如何工作的?
Map.get() API 获取关键对象 ar 方法参数并返回相关值(如果在 Map 中找到)。
String val = map.get("key");与 put() API 类似,查找存储桶位置的逻辑与 get() API 类似。使用最终哈希值定位桶后,将检查索引位置的第一个节点。
如果第一个节点是 TreeNode 类型,则 TreeNode.getTreeNode(hash, key) API 用于搜索相等的键对象。如果找到这样的 TreeNode,则返回该值。
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);如果第一个节点不是 TreeNode,则搜索以链表方式进行,并且在每次迭代中检查 next 属性,直到找到匹配的 key 对象找到一个节点。
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null); 六,结论
本 Java 教程讨论了 HashMap 类的内部工作。它讨论了如何分两步计算散列,以及如何使用最终散列在节点数组中查找存储桶位置。我们还了解了在重复键对象的情况下如何解决冲突。
快乐学习!!
地址:https://www.cundage.com/article/how-hashmap-works-in-java.html
相关阅读
![Java HashMap 的内部工作 [Java 17]](/assets/img/thumbnail.png)